
Copilot is now available on my tools/machine at work. Sitting here asking it to run down information and help me make plans to conquer the world.... I think back to my younger days watching Star Trek episodes on Television. Captain Kirk would ask the computer for information the 'ship' would spit it out in seconds.
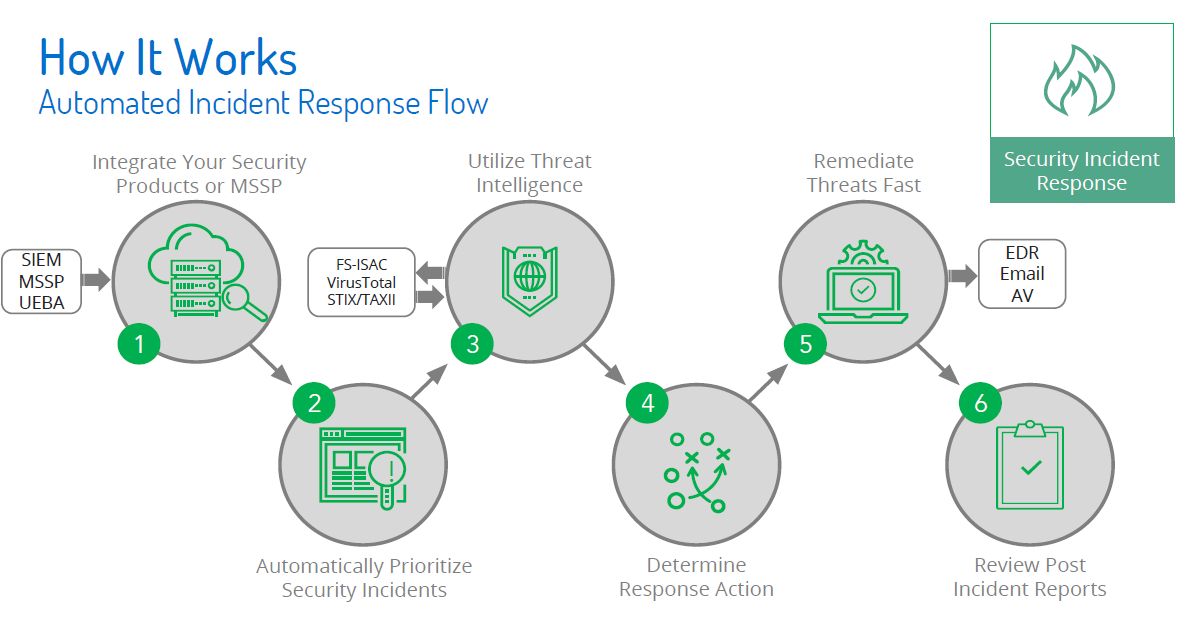
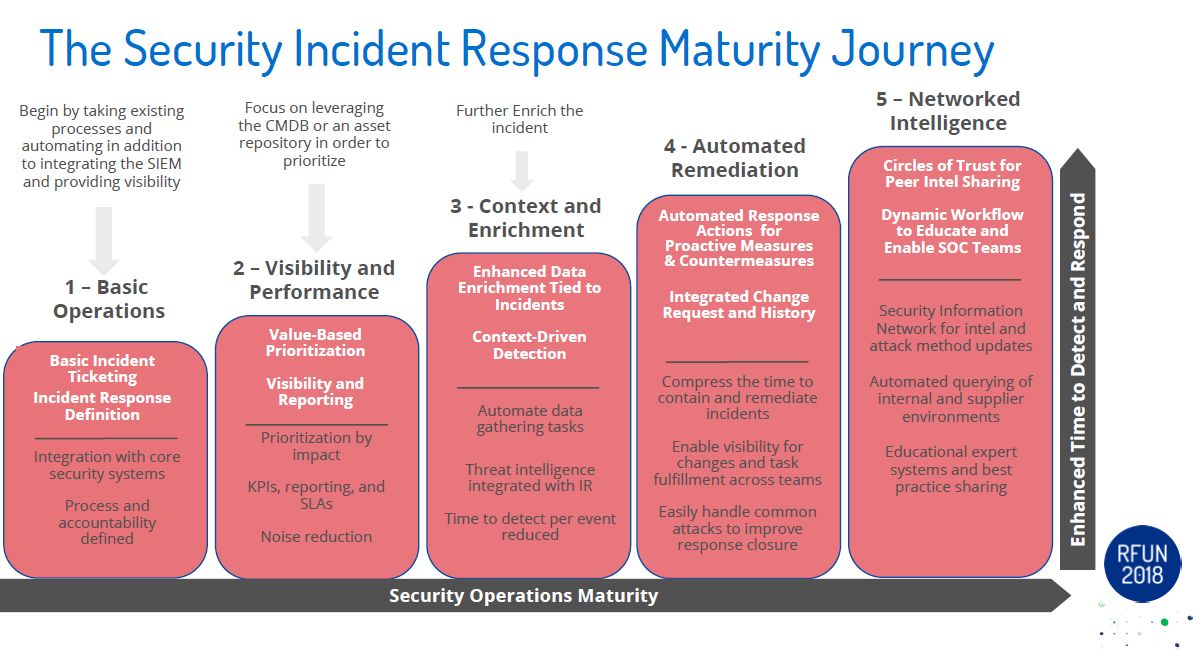
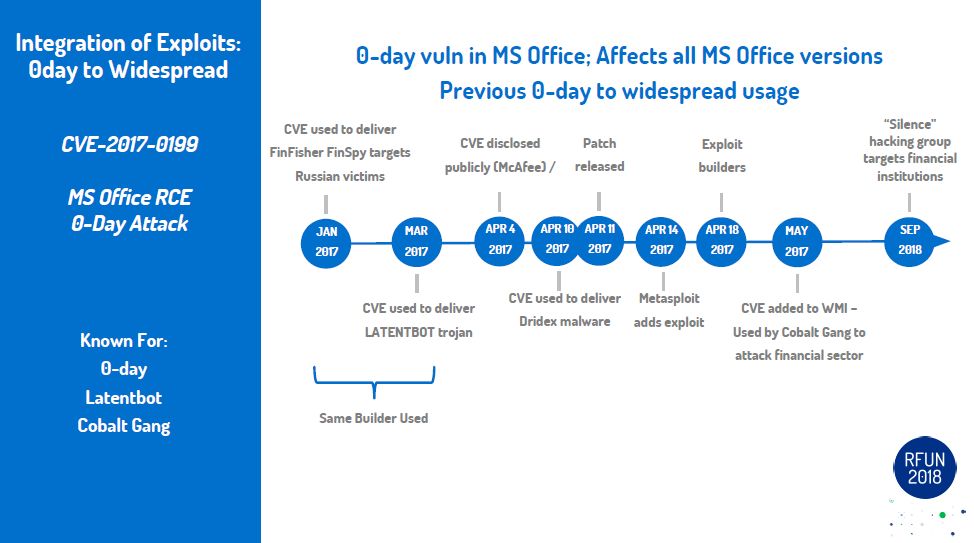
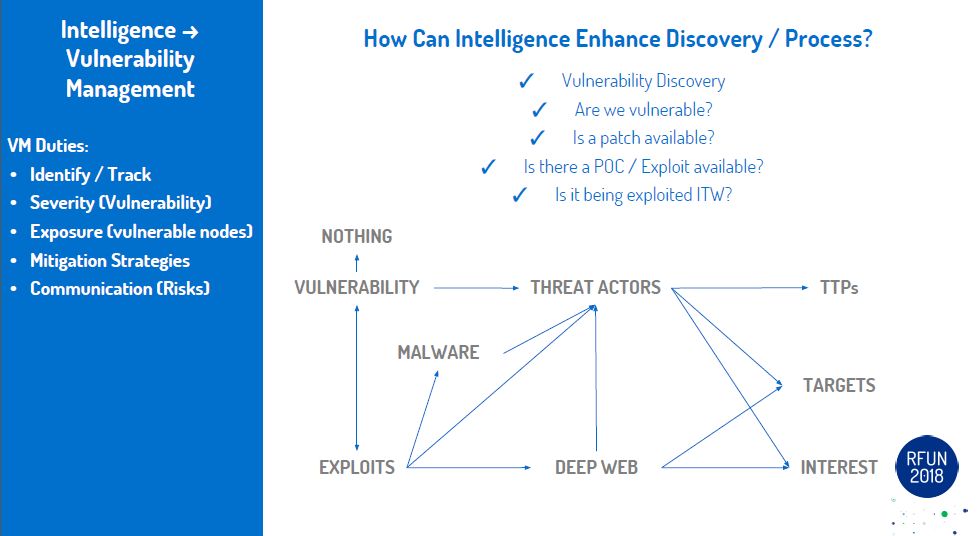
Fast forward to the present. We have almost reached this reality, minus the space travel and aliens.. But that isn't too far off either. The next step will be how fast can you go from a question to answer to action. Once the machines are able to process commands directly from output from Copilot/ChatGpt/etc we will only be limited by our imagination. In my yesteryear I did product evaluations. One of the areas that was fascinating to me was the SOAR field (security orchestration automation and response (SOAR)). With a SOAR framework you could put different pieces of a workflow together to accomplish different use cases and/or tasks. Each piece a step in process to accomplish the overall goal. Pulling and pushing information from different tools/platforms. Using that information to decide on next steps in the adventure. The next few years in tech will be pretty amazing. Keep an open mind and don't limit your imagination.
Bartlett
Fast forward to the present. We have almost reached this reality, minus the space travel and aliens.. But that isn't too far off either. The next step will be how fast can you go from a question to answer to action. Once the machines are able to process commands directly from output from Copilot/ChatGpt/etc we will only be limited by our imagination. In my yesteryear I did product evaluations. One of the areas that was fascinating to me was the SOAR field (security orchestration automation and response (SOAR)). With a SOAR framework you could put different pieces of a workflow together to accomplish different use cases and/or tasks. Each piece a step in process to accomplish the overall goal. Pulling and pushing information from different tools/platforms. Using that information to decide on next steps in the adventure. The next few years in tech will be pretty amazing. Keep an open mind and don't limit your imagination.
Bartlett









 RSS Feed
RSS Feed
